
Reasoning with Fewer Eyes: Efficient Visual Token Withdrawal for Multimodal Reasoning
Published in NeurIPS 2025 Workshop on Efficient Reasoning, 2025
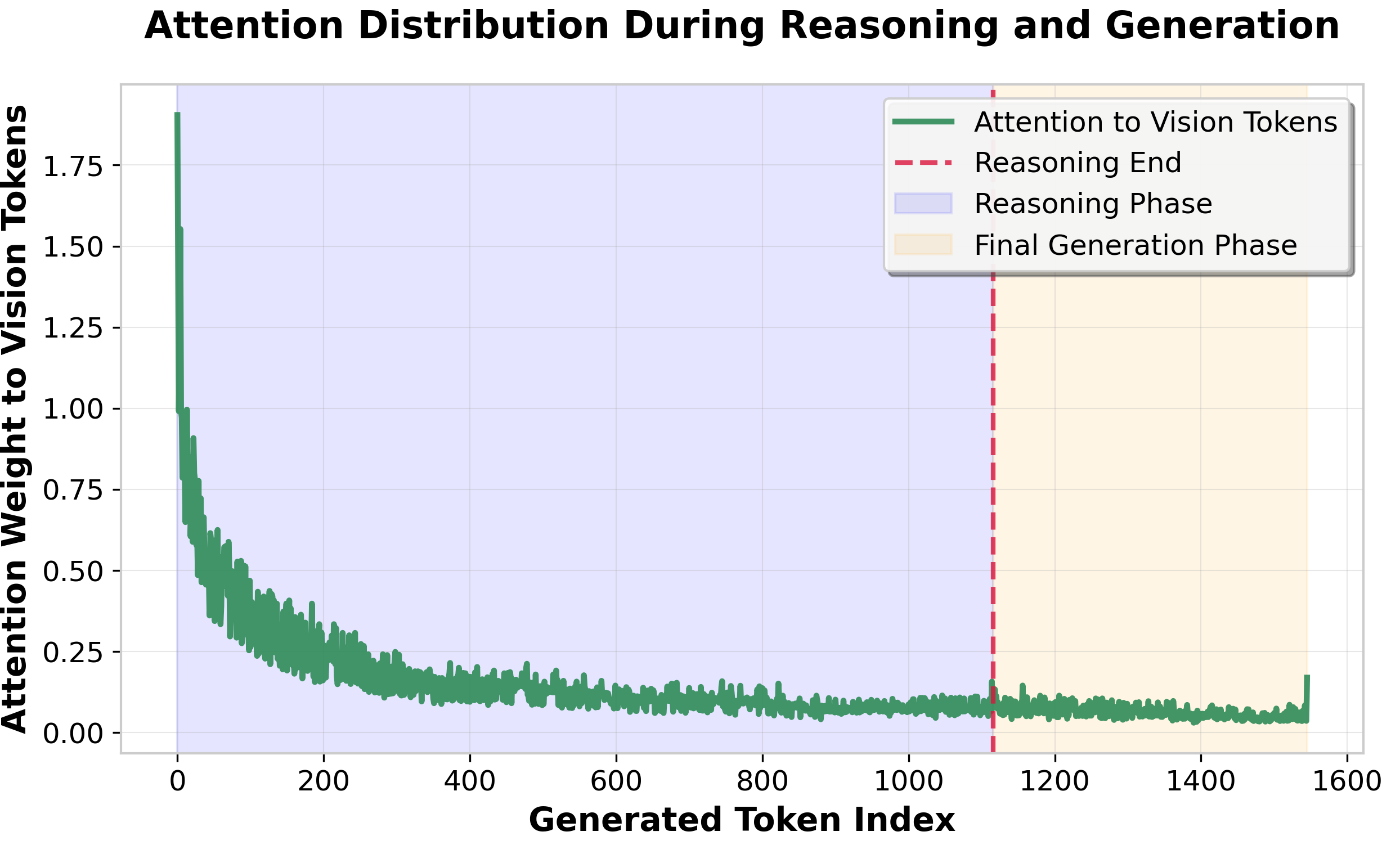
This paper introduces M-step Vision Withdrawal (MVW), a simple, training-free method to accelerate multimodal reasoning by selectively removing visual tokens during the autoregressive generation process. Our approach is motivated by the empirical observation that the attention devoted to vision tokens consistently drops after the initial text tokens are generated, as the model shifts from visual grounding to abstract reasoning.
The MVW method removes all vision tokens after generating the first M text tokens or after the end-of-reasoning token (e.g., </think>) is produced. This technique significantly reduces inference time and memory usage, and is fully compatible with popular efficiency techniques like KV caching and FlashAttention.
We evaluate MVW on multimodal mathematical reasoning benchmarks, MathVerse and WeMath, demonstrating that the method consistently matches or outperforms baselines in terms of reasoning accuracy, while reducing TFLOPS by up to 55,9%.
Recommended citation: Andrea Ramazzina, Tobias Haab, David Fitzek, Stefano Gasperini, Jonas Uhrig, and Mario Bijelic. (2025). "Reasoning with Fewer Eyes: Efficient Visual Token Withdrawal for Multimodal Reasoning." NeurIPS 2025 Workshop on Efficient Reasoning.
Download Paper